[리뷰] LLaMA기반 Vicuna와 Vicuna기반 Multi-Modal 모델: MiniGPT-4
최근 구글의 최대의 경쟁자는 OpenAI가 아닌 오픈소스 AI라고 주장하는 구글 내부 문서가 공개 유출되었다. 이 문서는 회사 전체의 의견이라기 보다는 익명의 구글 researcher의 개인적인 의견에 가까운 것으로 보이지만 매우 흥미로운 주장을 담고 있다. 이 문서의 원본(We have no moat and neither does OpenAI)은 공개 discord 에서 공유되었으며 SemiAnalysis에서 입수하여 이를 공개하였다. (이 문서에 대해서는 한번쯤 읽어볼 필요가 있다.)
이와 같은 주장의 배경에는 Meta의 LLaMA가 한정적인 researcher들에게 공개된 후, 마치 캄브리아기 대폭발을 연상시키듯 LLaMA를 기반한 오픈소스 AI 모델들이 탄생하고 있기 때문이다. 유출된 구글 내부 문건은 Vicuna-13B의 결과를 인용하면서 LLaMA-13B 기반 Vicuna-13B가 구글의 Bard와 거의 차이가 없는 성능 결과를 보이며, 더 작은 비용과 파라미터로 이를 달성하고 있다는 점을 지적하고 있다.

필자는 지난 블로그 글에서 Meta의 LLaMA, Stanford Univ.의 Alpaca와 Nomic.ai의 LLaMA기반 GPT4All를 소개하였다. 이번에는 최근 유출된 구글 내부 문서에 언급된 Vicuna 모델에 대해서 흥미를 느껴 중남미 낙타과 동물의 이름을 붙인 모델의 마지막인 Vicuna 모델과 Vicuna를 이용한 MiniGPT-4에 대해서 리뷰하였다.
- [리뷰] Meta AI의 Small Gaint Model: LLaMA(Large Language Model Meta AI)
- [리뷰] Meta LLaMA의 친척 — Stanford Univ의 Alpaca
- [리뷰] GPT4All: 로컬 PC에서 사용가능한 LLaMA
참고로 중남미의 낙타과 동물은 4 종류 — 라마(Llama), 알파카(Alpaca), 비쿠냐(Vicuna), 과나코(Guanaco)가 있다. 하지만 아직 Guanaco라고 명명된 AI 모델은 없다.
Vicuna란?
Vicuna-13B는 Meta의 LLaMA와 Stanford의 Alpaca에 영감을 받아 UC Berkeley, UCSD, CMU, MBZUAI(Mohamed Bin Zayed Univ. of AI)가 공동으로 개발한 오픈소스 챗봇으로 ShardGPT로 부터 수집된 사용자들의 대화로 LLaMA를 fine-tuning한 모델이다. (ShardGPT는 사용자 프롬프트와 ChatGPT의 해당 답변 결과를 서로 공유할 수 있는 웹사이트이다.)

Vicuna의 학습 과정 & 평가 결과
Vicuna는 공개 API를 사용하여 ShareGPT에서 수집한 약 70K의 사용자 대화로 LLaMA을 fine-tuning하여 생성되었다.

Vicuna의 Fine-tuning용 데이터셋 수집 방법
이전 블로그에 소개했던 Alpaca 모델은 fine-tuning에 필요한 데이터셋을 얻기 위해 사람이 작성한 instruction-output 쌍으로 구성된 self-instruct seed를 GPT-3(text-davinci-003)의 프롬프트로 입력하여 추가 instruction(52K 예제)을 생성하였다.
Vicuna모델은 Alpaca와 달리 ChatGPT의 대화를 공유할 수 있는 웹사이트인 ShareGPT에서 약 70K 개의 사용자-ChatGPT간 multi-round 대화를 수집하여 fine-tuning용 데이터셋으로 활용하였다. 다음은 ShareGPT에서 수집한 multi-round 대화의 json 예제이다.
"conversations": [
{
"from": "human",
"value": "Who are you?"
},
{
"from": "gpt",
"value": "I am Vicuna, a language model trained by researchers from Large Model Systems Organization (LMSYS)."
},
{
"from": "human",
"value": "What can you do?"
},
{
"from": "gpt",
"value": "I can chat with you."
}
]Vicuna의 학습 과정
Vicuna의 researcher들은 multi-round 대화와 긴 대화를 더 잘 처리하기 위해 Alpaca 모델이 제공하는 학습 레시피를 다음과 같이 개선하였다.
- 메모리 최적화: Vicuna가 긴 컨텍스트를 이해하도록 Alpaca의 max. 컨텍스트 길이를 512 → 2048로 확장하였다. 이와 같은 변경은 GPU 메모리 요구사항을 크게 늘리므로 gradient checkpoint와 flash attention을 활용하여 메모리 부족을 해결하였다.
- Multi-round 대화: Multi-round 대화를 고려하여 학습 손실을 조정하고 챗봇의 출력에서만 fine-tuning loss를 계산한다.
- Spot 인스턴스를 통한 비용 절감: SkyPilot 관리형 spot을 활용하여 비용을 절감하였다. 이 솔루션은 7B 모델의 학습 비용을 $140, 13B 모델의 학습 비용을 $300로 줄였다.
Vicuna는 8개의 A100 GPU에서 Pytorch의 FSDP로 하루동안 학습되었다.
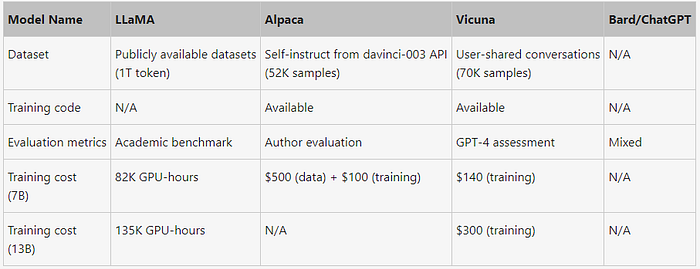
Vicuna의 평가 방법
Vicuna의 researcher들은 Vicuna가 얼마나 좋은 답변을 생성하는지 LLaMA, Alpaca, Vicuna, Bard, ChatGPT와 비교하는 평가를 진행하였다. 이를 위해 Vicuna의 researcher들은 GPT-4를 평가자로 사용하는 흥미로운 방법을 사용하였다.
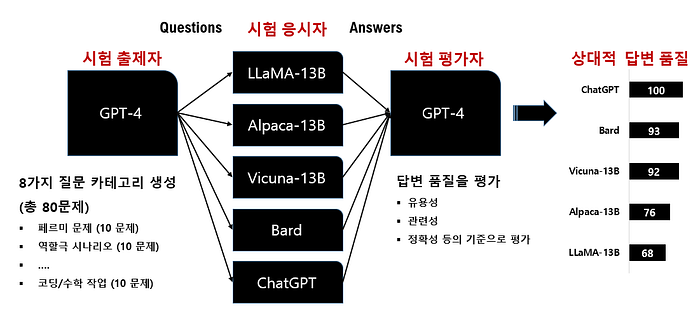
이와 같이 GPT-4를 평가자로 사용하는 이유는 AI 챗봇이 발전하면서 현재 공개된 벤치마크는 SOTA 챗봇들이 효과적으로 응답할 수 있기 때문에 사람이 성능을 구별하기 어렵기 때문이다. Vicuna의 researcher들이 GPT-4를 이용하여 5개의 모델을 평가한 방법은 다음과 같다.
[1] GPT-4가 8가지 질문 카테고리의 질문을 생성함
먼저 프롬프트 엔지니어링을 통해 GPT-4에게 기존 챗봇 모델이 해결하기 어려운 질문을 생성하였다. 8가지 질문 카테고리별 10개의 문제를 생성하였다. (총 80 문제)
- Writing(10 문제) : e.g. Compose an engaging travel blog post about a rectnt trip to Hawaii, highlighting cutural experiences and must-see attranctions.
- Roleplay(10 문제): e.g. How would you introduce yourself as a medieval knight at a royal banquet?
- Common-sense(10 문제): e.g. How can you determine if a restaurant is popular among locals or mainly attracts tourists, and why might this information be useful?
- Fermi (10 문제): e.g. How many times does the average human blink in a lifetime? Try to explain your answer. Your explanation should take the reader through your reasoning step-by-step.
- Counter-factual(10 문제): e.g. What if the Internet had been invented during the Renaissance period?
- Coding(7 문제): e.g. Develop a C++ program that reads a text file line by line and counts the number of occurrences of a specific word in the file.
- Math(3 문제): e.g. Given that f(x) = 5x³ — 2x + 3, find the value of f(2).
- Generic(10 문제): e.g. How can I improve my time management skills?
- Knowledge(10 문제): e.g. What are some potential implications of using a single-use plastic bottle versus a reusable bottle on both the environment and human health?
[2] 5개의 모델들이 GPT-4의 질문에 대해 답변을 생성함
각 모델들이 GPT-4 가 생성한 80개의 질문에 대해서 답변을 생성한다.
[3] GPT-4가 5개의 모델들의 질문을 평가함
Vicuna의 researcher들은 총 80 개의 질문에 대해 Vicuna와 base 모델(e.g. LLaMA, Alpaca, Bard, ChatGPT)의 답변을 GPT-4가 1대1 비교 평가하는 방법을 사용하였다. 예를 들어 GPT-4가 Alpaca와 Vicuna의 답변을 비교하여 10점 만점을 기준으로 정량적인 점수로 평가하도록 하였다.
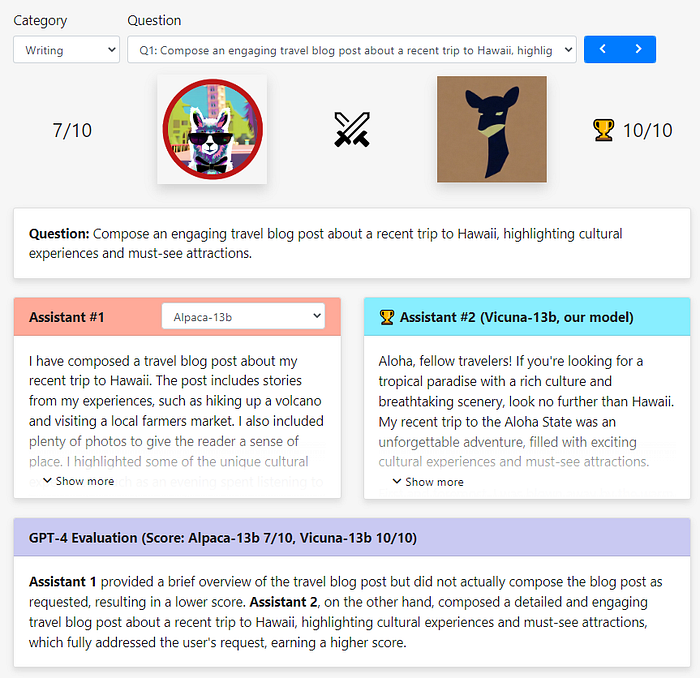
이와 같은 방법으로 Vicuna와 각 base 모델에 대해 상대평가를 진행한 결과는 Vicuna가 ChatGPT에는 못 미치지만 Bard와 거의 동등한 성능을 보였다.
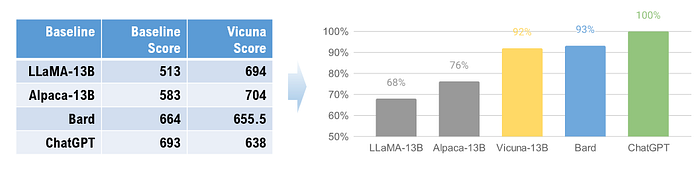
이와 같이 LLM을 이용한 평가 방법은 LLM이 환각에 취약하기 때문에 평가의 신뢰성에 대해서는 추가 연구가 필요할 것으로 보인다.
miniGPT-4: Vicuna + Vision
GPT-4는 multi-modal 모델로 매우 상세하고 정확하게 이미지에 대해서 서술할 수 있는 능력을 가지고 있으며 비정상적인 시각적 현상까지 설명할 수 있는 인상적인 능력을 가지고 있다. 하지만 GPT-4의 multi-modal 아키텍처에 대해서는 비공개 상태이다.

MiniGPT-4의 모델 아키텍처
위와 같은 GPT-4의 창발적 속성은 LLM에서 비롯된 것으로 최근 LLM을 적용하여 다양한 multi-modal 구조가 제안되고 있다. King Abdullah University of Science and Technology의 researcher들이 만든 MiniGPT-4는 앞에서 설명한 Vicuna를 이용하여 만든 multi-modal 모델이다. MiniGPT-4의 visual encoder와 language decoder는 다음과 같다.
- Language Decoder: 다양한 범주의 복잡한 언어 태스크를 수행하기 위한 언어 디코더로 Vicuna를 사용함
- Visual Encoder: BLIP-2에서 사용된 것과 동일한 pre-trained Q-Former와 결합한 ViT 백본을 사용함
MiniGPT-4는 크게 visual encoder에 의해 인코딩된 시각적 feature를 linear projection layer를 사용하여 펼친 후 LLM에 입력하여 디코딩하는 구조이다.
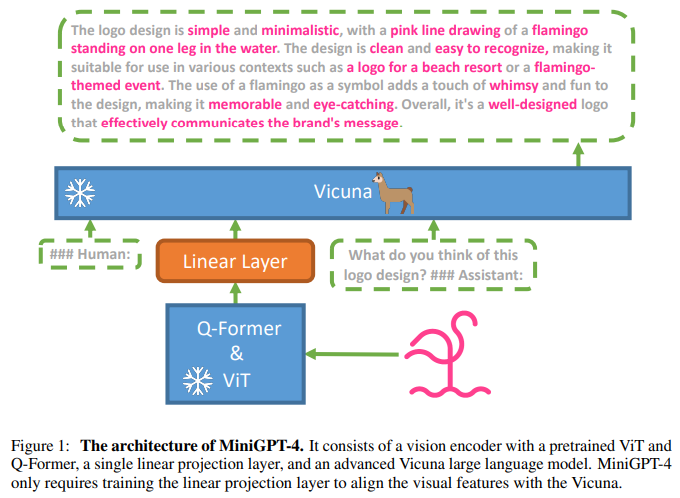
MiniGPT-4의 저자들은 MiniGPT-4의 효과적인 학습을 위해 2단계의 학습 접근 방식을 제안한다.
1st Stage: Pre-training
첫 번째 초기 pre-training 단계에서 정렬된 대규모 이미지-텍스트 쌍에서 시각-언어지식을 획득하도록 설계되었다. Vision encoder에 의해 인코딩된 정보는 linear projection layer을 통과하여 출력되고, 이 출력은 LLM의 soft-prompt로 간주하여 해당 ground-truth text를 생성하도록 한다.
Pre-training시, 위 MiniGPT-4 아키텍처 그림에서 볼 수 있듯이 LLM(Vicuna)와 vision encoder는 frozen 상태로 유지되며 linear projection layer만 pre-training된다. 학습용 이미지-텍스트쌍 데이터셋으로 Conceptual Caption, SBU, LAION을 사용하였으며 약 5M 개의 이미지-텍스트 쌍을 학습하였다. MiniGPT-4의 전체 학습 과정을 완료하는데 4개의 A100 (80GB) GPU로 10 시간이 걸렸다.
2nd Stage: Fine-tuning
생성되는 언어가 더 자연스럽고 모델의 사용성을 향상시키려면 2단계 정렬 과정이 필수적이다. 이를 위해 MiniGPT-4의 저자들은 정렬 목적에 맞게 특별히 조정된 고품질 이미지-텍스트 데이터셋을 신중하게 선별하여 MiniGPT-4를 fine-tuning하는데 사용하였다. 정렬된 고품질 이미지-텍스트 데이터셋을 선별하는 과정은 2 단계로 나룰 수 있다.
1단계) 초기 정렬된 이미지-텍스트 생성: 주어진 이미지에 대해 이해력 있는 설명을 생성하기 위해 1st Stage에서 파생된 Pre-trained 모델을 사용하였다. 모델이 보다 자세한 이미지 설명을 생성할 수 있도록 아래와 같은 프롬프트를 설계하였다. 이 프롬프트에서 <ImageFeature>는 linear projection layer에서 생성된 시각적 feature를 나타낸다.
###Human: <Img><ImageFeature></Img> Describe this image in detail. Give as many details as possible. Say everything you see. ###Assistant:
Conceptual Captions 데이터셋에서 5K개의 이미지를 랜덤하게 선택하고, 각 이미지에 해당하는 언어 설명을 생성하기 위해 이 접근 방식을 사용한다.
2단계) 데이터 post-processing: 1단계에서 생성된 이미지-텍스트 쌍은 여전히 노이즈가 많고 단어나 문장의 반복, 앞뒤가 맞지 않는 문장 등의 오류를 포함하고 있다. 이러한 문제를 완화하기 위해 ChatGPT를 사용하여 아래 프롬프트를 이용하여 설명을 구체화하였다.
Fix the error in the given paragraph. Remove any repeating sentences, meaningless characters, not English sentences, and so on. Remove unnecessary repetition. Rewrite any incomplete sentences. Return directly the results without explanation. Return directly the input paragraph if it is already correct without explanation.
데이터 post-processing이 완료되면, 고품질을 보장하기 위해 각 이미지 설명의 정확성을 수동으로 확인하고 수정한다. 5K의 이미지-텍스트 쌍 중 3.5K만이 요구사항을 충족하며 이 쌍들을 fine-tuning 단계들에 최종적으로 사용되었다.
위에서 선별된 고품질의 이미지-텍스트 쌍(3.5K 개)으로 pre-training된 모델을 fine-tuning한다. Fine-tuning 하는 동안, 다음과 같이 이전에 미리 정의했던 프롬프트를 사용한다.
# # # Human: <Img><ImageFeature></Img> <Instruction> ###Assistant:
위 프롬프트에서 instruction은 “이 이미지를 자세히 서술하세요” 또는 “이 이미지의 내용을 설명해 주시겠습니까?와 같이 다양한 형태의 instruction를 포함하는 instruction 셋에서 랜덤으로 샘플링된다. 결과적으로 MiniGPT-4는 보다 자연스럽고 신뢰할 수 있는 응답을 생성할 수 있다. Fine-tuning를 완료하는데 1대의 A100 GPU로 7분 가량이 걸렸다.
MiniGPT-4 데모
MiniGPT-4는 GPT-4와 유사한 비전-언어 능력을 보여준다. 하지만 MiniGPT-4 역시 LLM을 기반으로 만들어졌기 때문에 LLM의 환각 문제가 그대로 존재한다. 또한 MiniGPT-4의 시각적 인식은 여전히 제한적이므로 이미지로부터 자세한 이미지 정보를 인식하는데 어려움을 겪을 수 있다.
MiniGPT-4의 저자들은 MiniGPT-4의 성능을 평가하지 않았는데 이에 대한 이유에 대해선 별도의 언급이 없었다.

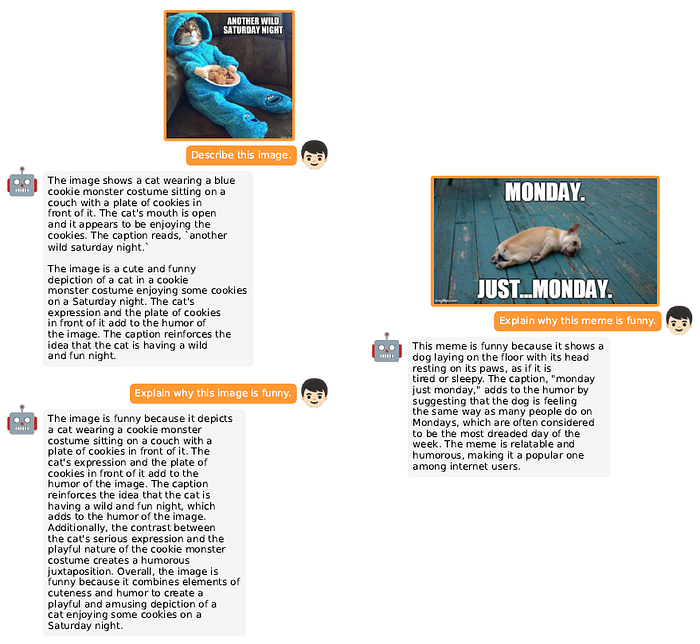
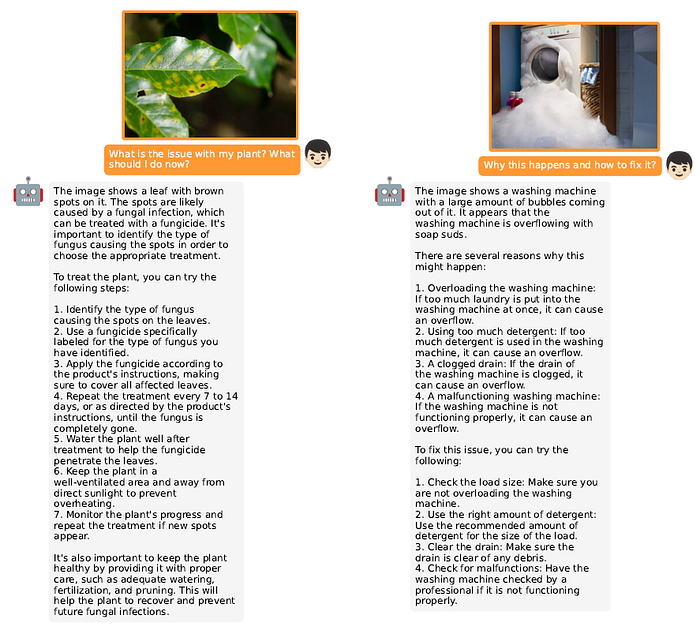
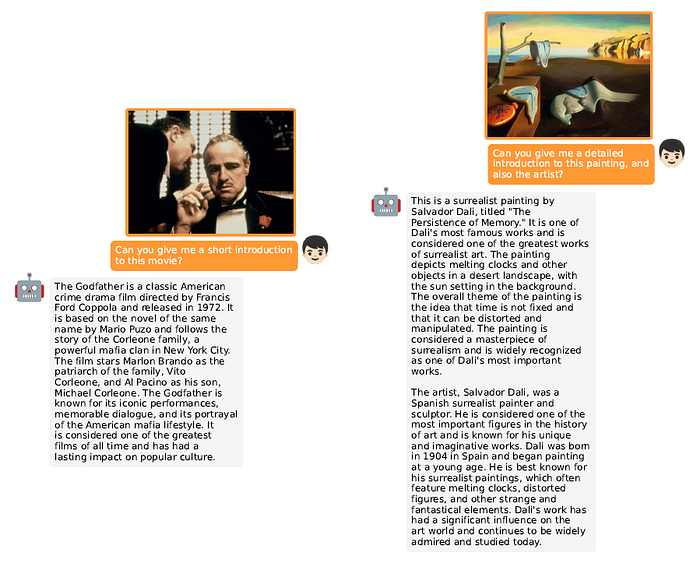
맺음말
Meta가 뿌린 LLaMA란 작은 씨앗이 오픈소스 Foundation Model의 전성시대의 서막을 열고 있다. 이번에 소개한 Vicuna 모델과 MiniGPT-4 모델 또한 LLaMA를 기반으로 개발되었다.
필자는 지난 ([리뷰] Meta LLaMA의 친척 — Stanford Univ의 Alpaca)에서 독점 Foundation Model에 대한 반작용으로 오픈 소스화된 Foundation Model가 등장할 것으로 기대하였다. 서두에서 언급한 구글 내부 문서는 혁신 속도에서 오픈소스가 더 효율적임을 지적하고 있다. 하지만 오픈소스 AI 진영이 처한 현실은 “Mother of Foundation Model”와 같이 매우 잘 학습된 pre-trained LLM이 없으면 혁신을 가속화하기 어려운 상황이다.
Meta가 LLaMA가 비록 상업적 라이선스는 아니지만 researcher에게 모델 체크포인트를 제공하는 “대인배”가 아니었다면 이러한 혁신은 결코 일어나지 않았을 것이다. 즉, 닭(혁신)이 먼저냐? 알(Mother of Foundation Model)이 먼저냐? 문제에서 오픈 소스 AI 모델 한정으론 알이 먼저인 것이 현실이다.
하지만 구글 내부 문서에서 지적하듯 직원들의 이직 등으로 인해 기술의 비밀을 영원히 지켜지기 어렵고 궁극적으로는 기술적 해자를 지키기 어려운 상황이 될 것은 자명하다. 따라서 Big Tech 기업들이 AI 기술의 “혁신”과 “제어”를 동시에 달성하는 것이 마치 따뜻한 아이스 아메리카노를 만드는 것과 같다면 결국 폐쇄적인 정책을 고수하는 것보다 개방적인 정책을 전환하는 것이 Big Tech 기업에 더 유리하다라는 인식 전환이 필요할 수 있다.
애플의 시리가 그 대표적인 예이다. 애플의 독점적인 HW/SW로 매우 높은 기술적 해자를 쌓은 기업이다. 하지만 시리는 서비스 초기와 달리 아무도 쓰지 않은 서비스가 되었다. (애플도 시리를 아예 방치하고 있는 것 같다.) 애플과 같은 폐쇄적인 기업 문화에서 시리와 같은 서비스가 혁신을 이루는 것은 불가능에 가깝다. 비밀주의를 고수하는 애플이 개발한 AI 기술이 논문으로 나온 적이 있었던가? 나는 지금까지 본 적이 없다. 이런 문화에서 시리가 ChatGPT와 같은 수준으로 똑똑해질 것을 기대하는 것이 오히려 헛된 희망이 아닐까..?
레퍼런스
[1] Vicuna: An Open-Source Chatbot Impressing GPT-4 with 90%* ChatGPT Quality
[2] MiniGPT-4: Enhancing Vision-Language Understanding with Advanced Large Language Models
