[리뷰] Meta AI의 논문 LIMA(Less Is More for Alignment): 결국 LLM의 Pre-training이 가장 중요하다?
최근 Meta AI는 CMU, USC, Tel Aviv Univ.의 researcher들과 함께 “LIMA: Less Is More for Alignment”라는 제목의 논문을 공개하였다.
LIMA 논문의 저자들은 LLM의 대부분의 지식은 pre-training 중에 학습된 것이며, alignment는 단지 사용자와 상호작용하는 assistant-style을 학습하는 간단한 프로세스라고 주장한다.
이를 뒷받침하기 위해 RLHF와 같은 강화학습없이 잘 선별된 1K 개의 프롬프트로 LLaMA 65B를 fine-tuning 한 LIMA 모델이 RLHF기반 Davinci-003 모델(GPT-3.5)보다 더 좋은 성능을 보이며 GPT-4와 성능 비교 테스트를 하였을 때도 18%는 우세, 25%는 동등한 성능 결과를 보여주었다.
즉, 엄선된 1K 예제만으로 LLaMA를 fine-tuning한 LIMA 모델이 GPT-3.5와 GPT-4의 중간 정도의 성능을 제공하는 것이다. 본 post에서는 최근 LLM 연구의 큰 흐름을 살펴보고 LIMA 연구 결과에 대한 의미에 대해서 알아보도록 하겠다.
최근 LLM 발전 동향
최근 LLM의 동향은 아래와 같은 크게 두 가지의 큰 흐름으로 구분할 수 있다.
(1) GPT-3 ➜ Instruct-GPT
GPT-3(‘20)은 175B, GPT-4(‘23)는 1T(주:*예측치)의 거대한 파라미터을 가진 대표적인 SOTA LLM으로 학습 데이터 구축 및 학습에 막대한 비용이 필요하다. GPT는 놀라운 능력을 발휘함에도 불구하고 실제 세계에 적용하기 위해선 바람직하지 못한 출력을 수정해야 한다.
즉, 학습 데이터셋에 포함된 사회적인 bias (인종, 성별, 가치관 등)가 그대로 GPT에 반영되는 경우가 있기 때문이다. 따라서 Pre-training된 GPT 모델은 alignment를 위해 InstructGPT 논문에서 소개된 RLHF(Reinforcement Learning with Human Feedback)과 같은 방법을 사용하여 인간의 선호도를 모델의 성능을 개선하는데 사용한다. 하지만 RLHF는 인간 라벨러를 동원하여 프롬프트를 수집하고 LLM에 인간의 선호도를 학습시키므로 모델 생성에 많은 비용이 필요하다.
(2) Chinchilla ➜ LLaMA ➜ Alpaca (LLaMA + Self-Instruct)
Google Deepmind에서 발표된 Chinchilla 모델(‘22)은 제한된 compute 예산 아래에서 모델의 최적 성능을 달성하기 위한 방법을 제안한다. Chinchilla는 제한된 FLOPS에서 최적 성능을 달성하기 위한 모델 크기와 학습 token의 조합을 계산하는 방법을 제안하며 70B 파라미터로 280B 파라미터의 Gopher 모델보다 더 우수한 성능을 달성하였다. 즉, 기존 LLM이 큰 파라미터 개수에 비해 과소 적합되어 있다는 것을 입증한 것이다.
Meta는 Chinchilla의 결과를 계승하여 추론에 유리하도록 GPT-3 175B보다 더 작으면서 성능은 더 우수한 LLaMA (’23. 4가지 버전 7B, 13B, 33B, 65B)을 발표하였다. (LLaMA 13B은 GPT-3 175B를 모든 벤치마크에서 압도하는 결과를 보여준다) LLaMA는 RLHF이 적용되지 않은 LLM으로 챗봇으로 동작할 수 없기 때문에 추가적인 학습 방법론이 필요하다. LLaMA는 연구자들에게 제한적으로 모델 weight를 공개되면서 Alpaca를 비롯한 LLaMA 계열의 수많은 연구용 모델이 탄생하는데 기여하였다.
스탠포드 대학의 Alpaca는 Self-Instruct 논문의 방식을 채용하여 기존 pre-training된 LLM(text-davinci-003)을 이용하여 instruction tuning용 데이터셋(52K)을 생성한 후, Meta의 LLaMA 7B 모델을 52K 데이터셋으로 supervised fine-tuning 하였다. Alpaca가 갖는 의미는 제한된 학습 예산(총 < $600)으로 사용자의 선호도 데이터셋을 사용하는 RLHF와 달리 사람이 생성한 데이터셋을 최소로 사용하여 고품질의 Instruction Following Model을 만들어냈다는 점이다.
위와 같은 큰 흐름으로부터 다음과 같은 LLM의 발전 동향을 유추해볼 수 있다.
- 초기에는 LLM의 성능 개선을 위해 단순히 LLM의 파라미터 개수를 늘리는데 집중하였다면, 최근에는 추론 속도와 제한된 compute 예산을 고려하여 충분한 성능을 제공할 수 있는 좀더 작은 모델을 선호한다.
- LLM의 alignment를 위해 대규모의 사용자 데이터셋과 상댱량의 컴퓨팅이 필요하는데 이를 줄이려는 노력을 진행 중이다.
LIMA(Less Is More for Alignment) 저자들의 가설
Meta AI의 LIMA 논문 저자들은 위의 (2)번 동향: Chinchilla ➜ LLaMA ➜ Alpaca (LLaMA + Self-Instruct)을 좀더 발전시켜 LLM의 지식과 능력은 pre-training 시 이미 획득된 것이며 alignment는 모델이 사용자와 상호 작용하는 스타일이나 형식을 학습하는 간단한 프로세스일 것이라는 가설을 세웠다. 즉 LLM의 성능을 높이기 위해 alignment 과정보다는 pre-training 과정이 더 중요하다는 것이다.

LIMA의 저자들은 이 가설을 입증하기 위해 잘 학습된 Pre-trained LLM 모델을 신중하게 선별된 1K의 학습 예제만으로 fine-tuning 하였을 때 모델 alignment가 가능하다는 사실을 테스트하였다.
Alignment 데이터 수집- (1) 커뮤니티 질문 및 답변
위의 가설을 입증하기 위해 LIMA의 저자들은 실제 사용자 프롬프트와 고품질 응답에 근접한 1K 개의 예제를 선별하였다. 1K의 학습 예제의 구성은 다음과 같다.
- 750개: Stack Exchange(400개), WikiHow(200개), Pushshift Reddit(150개)와 같은 커뮤니티 포럼에서 인기있는 질문과 답변을 선별
- 250개: 저자들이 수동으로 프롬프트와 응답을 작성한 예제. 태스크의 다양성을 최적화하고 일관된 응답 스타일을 강조하기 위해 추가
이 밖에 300개의 테스트 예제를 이용하여 LIMA와 SOTA 언어 모델들과 비교하였다.

다음은 LIMA의 저자들이 커뮤니티 포럼에서 예제를 선별하는 방법을 소개한다.
Stack Exchange (400 samples)
Stack Exchange는 활발한 커뮤니티 멤버와 운영진 덕분에 고품질의 컨텐츠를 유지하고 있다. LIMA의 저자들은 Stack Exchange에서 샘플링을 할 때 품질과 다양성 제어를 모두 적용하였으며 Stack Exchange의 샘플을 2개로 구분하였다.
- STEM 분야 (75개): 프로그래밍, 수학, 물리학 등
- Other 분야 (99개): 영어, 요리, 여행 등
다른 영역에서 더 균일한 샘플을 얻기 위해 각 세트(STEM, Other)에서 200개의 질문과 답변을 샘플링하였다. (temperature=3)
WikiHow (200 samaples)
WikiHow는 다양한 주제에 대해 240,000개 이상의 사용법 문서를 제공하는 온라인 wiki 스타일의 출판물이다. 누구나 WikiHow에 기여할 수 있지만, WikiHow의 문서는 엄격하게 관리되므로 거의 보편적으로 고품질 컨텐츠가 생성된다. 다양성을 보장하기 위해 우선 19개의 카테고리 중 한 카테고리를 샘플링한 후 그 안에 문서를 샘플링하여 WikiHow로부터 200개의 문서를 추출하였다.
Pushshift Reddit (150 samples)
Reddit은 세계에서 가장 인기있은 웹사이트 중의 하나로 사용자가 만든 하위 Reddit에서 컨텐츠를 공유하고, 토론하고 지지를 보낼 수 있다. Reddit은 도움을 주는 것보다 다른 사용자들 즐겁게 하는데 더 중점을 두는 경우가 있어서 post에 대한 진지하고 정보성 댓글보다 위트가 있고 비꼬는 댓글이 더 많은 표를 얻는 경우가 많다. 이를 피하기 위해 LIMA의 저자들은 r/AskReddit과 r/WritingPrompts 두 서브셋으로 샘플을 제한하고, 각 커뮤니티에서 가장 많은 지지를 받은 post들 중에서 샘플을 수동으로 선택하였다.
- r/WritingPrompts 서브셋: 사랑에 대한 시와 단편 SF 이야기와 같은 주제를 포함한 150개의 프롬프트와 고품질의 답변을 찾아 학습 데이터셋에 추가
- r/AskReddit 서브셋: 제목만 있고 내용은 없는 70개의 self-contained prompts을 찾아 테스트셋으로 사용
모든 데이터 인스턴스들은 Pushshift Reddit Dataset 에서 채굴되었다.
Alignment 데이터 수집- (2) 저자들이 작성한 예제
온라인 커뮤니티의 데이터외 다양성을 풍성하게 하기 위해 LIMA의 저자들이 직접 프롬프트를 수집하였다. 이를 위해 저자들을 그룹 A와 그룹 B로 나누고 각 그룹마다 250개의 프롬프트를 생성하였다.
- 그룹 A: 프롬프트 200개는 학습용, 프롬프트 50개는 개발용으로 선택함
- 그룹 B: 문제가 있는 일부 프롬프트를 필터링한 후, 그룹 B의 나머지 프롬프트 230개가 테스트에 사용됨
수동적으로 작성한 예제 외, 초자연적 명령(Super-naturalinstructions: generalization via declarative instructions on 1600+ tasks)에서 50개의 학습 예제를 샘플링하였다. 샘플링 방법은 요약, 의역, 스타일 전달과 같은 자연어 생성 태스크 50개를 선택하고 각 태스크에서 무작위로 하나의 예제를 선택하였다.
LIMA 학습 방법
LIMA는 LLaMA 65B을 1K 예시 학습 셋으로 fine-tuning하였으며 각 화자(speaker)를 구별하기 위해 각 발화 끝에 특별한 End of Token(EOT)를 도입하였다. Fine-tuning 시 hyper-parameter는 다음과 같다.
- AdaW optimizer 사용
- 15 epoch fine-tuning
- β1 = 0.9, β2 = 0.95
- Weight Decay = 0.1
- Learning rate는 warmup step 없이 초기 lr=1e-5로 설정하며, 학습이 끝날때까지 선형적으로 lr=1e-6까지 감쇠(decay)하도록 설정
- Batch Size = 32 examples (더 작은 모델은 64 examples)
- 2048 token보다 더 긴 텍스트는 잘라냄
- residual dropout 사용
평가 방법
실험 설정
LIMA의 저자들은 LIMA를 아래 5가지 베이스라인 모델과 비교하였으며 테스트 프롬프트는 300 개를 사용하였다. (Pushshift r/AskReddit: 70개, 그룹 B 소속 저자: 230개 → 총 300개)
- (1) Alpaca 65B: LLaMA 65B을 Alpaca의 52K 학습 데이터셋으로 fine-tuning한 모델
- (2) OpenAI의 DaVinci003: RLHF기반 LLM (GPT-3+RLHF)
- (3) OpenAI의 GPT-4: RLHF기반 SOTA LLM
- (4) Google의 Bard: PaLM 기반 LLM (주: 최근 Bard에 PaLM2가 적용되기 전에 LaMDA가 사용된 것으로 알고 있는데 LIMA 논문은 PaLM으로 설명하고 있음. 확인 필요)
- (5) Anthropic의 Claude: RL으로 학습된 52B 모델
LIMA와 각 baseline 모델을 비교하기 위해 테스트 프롬프트에 대해서 단일 응답을 생성하고 인간 crowd worker에게 LIMA와 baseline 모델의 출력을 비교하는 방식으로 평가를 진행되었다. 또한 LIMA의 저자들은 인간 대신 GPT-4로 교체하여 동일한 방식으로 평가를 진행하였다.
실험 결과
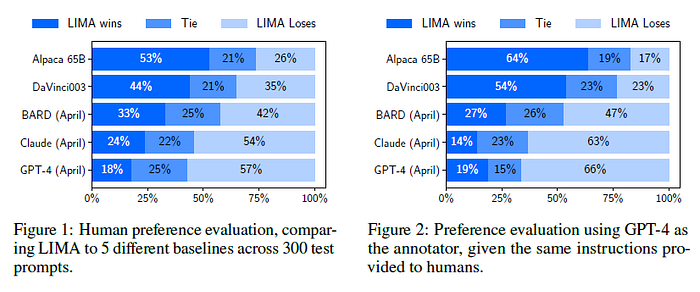
사람의 선호도 및 GPT-4를 이용한 선호도 평가 결과는 다음과 같다.
- LIMA(53%) vs Alpaca 65B(26%): LIMA보다 52배 큰 데이터셋 (1K vs 52K)으로 학습했음에도 불구하고 Alpaca보다 LIMA의 선호도가 더 높았다.
- LIMA(44%) vs DaVinci003(35%): 더 우수한 alignment 방법으로 여겨지는 RHLF로 학습되었지만 LIMA의 선호도가 더 높았다.
- LIMA(33%) vs Bard(42%), LIMA(24%) vs Claude(54%), LIMA(18%) vs GPT-4(57%): Bard, Claude, GPT-4는 LIMA에 비해 더 높은 선호도를 보였다. 재미있는 사실은 SOTA인 GPT-4로 선호도 평가를 하였을 때 사람의 선호도 측정 결과에 비해 Bard, Claude, GPT-4에 더 후한 점수를 주었다.
추가 분석
Baseline 모델은 학습 시 수백만 개의 사용자의 프롬프트를 고도로 fine-tuning한 모델이라서 LIMA와 동등한 비교가 어렵다. 따라서 LIMA의 저자들은 50개의 랜덤 예제를 수동으로 분석하여 절대적인 평가를 진행하였으며 각 예제를 3개의 카테고리 중 하나로 분류하였다.
- Fail: 응답이 프롬프트의 요구사항을 만족하지 못함
- Pass: 응답이 프롬프트의 요구사항을 만족함
- Excellent: 모델이 프롬프트에 대해 우수한 응답을 제공함
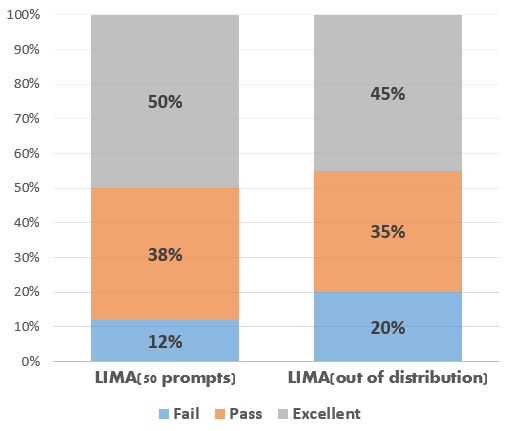
50개의 랜덤 예제에 대해서 테스트를 한 결과, LIMA 답변의 50%가 Excellent로 판정되었으며, Pass+Excellent의 비율은 88%로 나타났다. 추가로 LIMA가 학습하지 못한 예시 13개를 분석한 결과, 응답의 20%는 Fail, 35%는 Pass, 45%는 Excellent인 것을 알 수 있다. 비록 작은 샘플이지만 LIMA가 학습 분포(out of distribution) 밖에서도 유사한 절대 성능 통계를 달성하는 것으로 보아 일반화 가능성을 확인할 수 있다.
학습 데이터의 다양성, 품질, 양에 대한 영향성 분석
LIMA의 저자들은 Alignment을 위해 입력의 다양성과 출력 품질을 확장하면 측정 가능한 긍정적인 효과가 있는 반면, 양만 확장하면 그렇지 않을 수 있음을 관찰하였다. 이를 위해 제거 실험을 통해 학습 데이터의 다양성, 품질, 양이 미치는 영향을 조사한다.
실험 설정
학습용 파라미터와 동일한 hyper-parameter를 제어하면서 다양한 데이터셋에 대해서 LLaMA 7B를 fine-tuning한다. 그 다음 각 테스트셋 프롬프트에 대해서 5개의 응답을 샘플링하고 ChatGPT에 응답의 유용성을 1~6점 likert 척도로 평가를 요청하여 응답의 품질을 평가한다.

다양성
품질과 양을 통제하면서 프롬프트 다양성의 효과를 테스트하기 위해, LIMA의 저자들은 1) Excellent 응답을 가진 Heterogeneous 프롬프트가 있는 StackExchange 데이터와 2) Excellent 응답을 가진 Homogeneous 프롬프트가 있는 WikiHow 데이터에 대해 학습의 효과를 비교하였다. Stack Exchange를 샘플링하는 것과 동일한 방법에 따라 각 소스에서 2K개의 학습 example들을 샘플링하였다. 아래 그림은 Stack Exchange 데이터가 다양할수록 훨씬 더 높은 성능을 보인다.
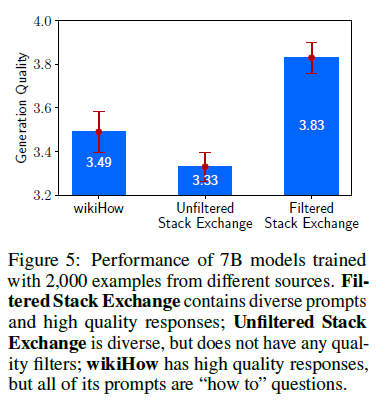
품질
LIMA 저자들은 응답 품질의 영향을 테스트하기 위해 품질 필터나 stylistic 필터없이 Stack Exchange로부터 2K examples를 샘플링한 데이터셋로 학습된 모델과 필터링된 데이터셋에서 학습된 모델을 비교하였다. 필터링된 데이터 소스와 필터링되지 않은 데이터 소스로 학습된 모델 간에 0.5 포인트의 유의미한 차이가 있음을 보여준다.
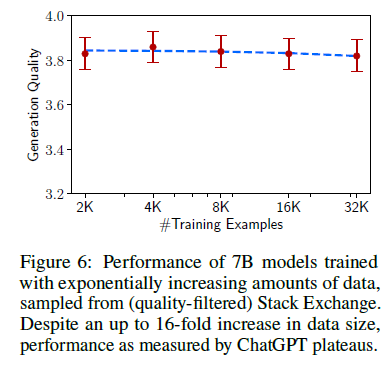
데이터 양
Example 수를 늘리는 것은 많은 ML 환경에서 성능을 개선하기 위해 잘 알려진 전략이다. 이 전략이 LIMA에 어떠한 영향을 미치는지 LIMA의 저자들은 Stack Exchange에서 학습 데이터셋을 기하급수적으로 증가시켜 샘플링한 후 학습한 결과를 비교하였다. 하지만 그 결과는 놀랍게도 학습 데이터셋을 두 배로 늘려도 응답 품질이 개선되지 않는 것을 확인할 수 있다.
이와 같은 결과는 alignment의 scaling law가 반드시 데이터셋 양에만 영향을 받는 것이 아니라, 고품질의 응답을 유지하면서 프롬프트 다양성의 함수임을 시사하고 있다.
멀티-turn 대화
LIMA 저자들은 멀티-turn 대화에 대해서도 테스트하였다. 10개의 실시간 대화에서 LIMA를 테스트하여 각 응답에 대해 Fail, Pass, Excellent 라벨을 붙였다. LIMA는 zero-shot 챗봇치고 놀라울 정도로 일관성있는 응답을 생성하였지만 10개의 대화 중 6개의 대화에서 3개의 상호 작용 이내에서 프롬프트를 따르지 않았다.
LIMA의 저자들은 LIMA의 대화 능력을 향상시키기 위해 LIMA의 저자들이 직접 작성한 10개의 대화와 Stack Exchange의 20개 코멘트 chain을 기반으로 총 30 개의 멀티-turn 대화 chain을 수집하였으며 대화 chain을 어시스턴트 스타일에 맞도록 편집하였다. 그 다음, 그들은 1K example과 30개 멀티-turn 대화를 조합한 1030 개 example로 pre-training한 LLAMA 모델을 fine-tuning하여 새로운 버전의 LIMA 버전을 만들었다. 아래 그림은 fine-tuning 전/후 실험 결과를 보여준다.
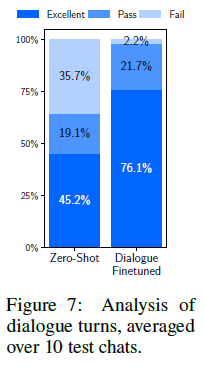
단지 30개의 멀티-turn 대화를 추가하여 fine-tuning한 LIMA 모델의 생성 품질이 크게 향상되었다. Excellent로 판정된 응답 비율이 45%에서 76.1%로 증가하였으며 zero-shot의 경우 42번의 turn 당 15번의 Fail이 발생하는 반면, fine-tuning한 경우 46번의 turn 당 1번의 Fail이 발생하여 실패율이 35.7%(=15/42)에서 2.2%(=1/46)로 크게 떨어짐을 알 수 있다.
Zero-shot 모델이 대화를 할 수 있는 사실뿐만 아니라 단 30개의 멀티-turn 대화로부터 LIMA의 대화 능력이 도약하는 점은 대화 능력이 pre-training 중에 학습되며 제한된 감독을 통해 그 능력을 불러 일으킬 수 있다라는 가설을 강화하고 있다.

맺은 말
LIMA의 저자들은 LLM를 잘 pre-training 할 경우, alignment를 위해 RLHF와 같은 값비싼 과정이 필요없이 엄선된 소수의 데이터셋만으로 supervised fine-tuning하여도 좋은 성능을 기대할 수 있다라고 주장한다.
LIMA의 저자들이 주장하는 것처럼 값비싼 RLHF를 사용하지 않아도 소수의 데이터셋만으로 손쉽게 alignment를 할 수 있다면 굉장히 좋은 방법일 것이다. 필자가 LIMA의 실험 결과에서 주목할만 것은 다음과 같다.
- LIMA의 저자들은 학습 데이터셋을 기하급수적으로 증가시켜도 LIMA의 응답 품질이 개선되지 않는 것을 확인하였다. 이는 데이터셋의 양보다 고품질 프롬프트와 프롬프트의 다양성이 중요하다라는 사실이다.
- 멀티-turn 대화의 성능을 개선하기 위해 단지 30개의 멀티-turn 대화를 fine-tuning하는 것만으로 멀티-turn 대화 성능이 비약적으로 향상되었다.
Pre-training을 잘하는 것이 RLHF 보다 더 좋은 성능을 내는지에 대한 실험적인 검증은 있었지만 왜 이러한 결과가 나오는지에 대한 분석 결과가 없어서 이를 이해하지는 못하였다.
LIMA의 저자들은 전제 조건으로 pre-training에서 이미 지식과 능력을 획득한다라고 하였는데 현재 pre-training은 unsupervised learning으로 대규모의 데이터셋을 학습하므로 pre-processing 과정에서 지금보다 추가적인 corpus의 품질 향상이 이루어져야 할 것으로 보인다.
이와 같은 변화라면 pre-processing 단계에서 이전보다 더 많은 시간과 비용을 지출해야 하므로 배보다 배꼽이 더 큰 상황이 될 수 있다.Pre-training 단계에서 LLM을 대규모 데이터셋으로 unsupervised learning 시 데이터셋의 noise와 bias를 pre-processing 시 충분히 필터링하지 못하였기 때문에 이를 alignment하기 위해 RLHF가 필요한 것이다.
마지막으로 baseline 모델과 LIMA를 비교함으로써 LIMA의 상대적인 성능을 측정하였는데 평가자의 주관적인 bias가 개입될 수 있는 여지가 있으므로 좀더 객관적인 MMLU과 같은 벤치마크를 사용하는 것이 좋지 않았을까 아쉬운 생각이 드는 논문이었다.
