Large Model 학습의 game changer, MS의 DeepSpeed ZeRO-1,2,3 그리고 ZeRO-Infinity
DeepSpeed ZeRO는 Large Model 학습에 본격적으로 Heterogeneous Computing을 활용하여 Large Model 학습에 필요한 비용을 절감할 수 있다.
0. Deep Learning Training의 Challenge
- Massive data으로 고품질 모델을 학습하는데 너무 느림
- 더 많은 HW 리소스를 투입에 비례하여 더 높은 throughput 얻을 수 없고 더 큰 모델을 학습할 수 있지 않음
- 더 높은 throughput을 달성한다고 하여 더 좋은 정확도를 얻을 수 있는 것도 아니며 더 빠르게 수렴되지도 않음
- 더 좋은 기술이 사용하기 쉬운 것은 아님
1. DeepSpeed Oveview
DeepSpeed는 MS가 만든 Large Model 학습을 위한 오픈소스이다. 특히 DeepSpeed의 ZeRO(Zero Redundancy Optimizer)는 대규모 분산 딥러닝을 위한 새로운 메모리 최적화 기술로 모델 및 데이터 병렬 처리에 필요한 리소스를 크게 감소시킬 수 있으며 학습할 수 있는 파라미터의 수를 크게 증가시킬 수 있다.
DeepSpeed는 다음 4가지 측면에서 탁월한 성능을 제공한다.
1) Model Scale
ZeRO-1은 100B 모델까지 학습가능하며, ZeRO-2는 200B 모델까지 학습가능하다. ZeRO-3(ZeRO-Offload)는 V100당 13B 파라미터를 학습할 수 있다.

2) Speed
Megatron-LM은 tensor-slicing model parallelism를 사용한다. Megatron-LM의 tensor-slicing model parallelism에 DeepSpeed ZeRO-2의 data parallelism을 추가하면 DeepSpeed가 Megatron-LM보다 10x 더 빠르다.

3) Scalability
디바이스 개수의 증가에 따라 super-linear speed-up을 달성할 수 있다. 녹색 그래프는 perfect linear scalability로 실제로 디바이스 개수에 따른 산술적인 성능이라면, DeepSpeed를 사용하면 perfect linear scalability보다 더 높은 성능을 보인다.
예를들어 머신을 2배로 증가시키면 시스템 throughput이 2배 이상 증가한다. 이는 DeepSpeed가 GPU 메모리 사용량을 줄여 Activation을 위한 가용 Device Memory을 높여 더 높은 batch size를 허용하므로 더 높은 GPU 효율성을 달성할 수 있으므로 super-linear speed-up을 달성할 수 있다.

4) Usability
DeepSpeed는 Pytorch 기반이며 몇 줄의 코드를 추가하면 DeepSpeed를 사용가능하다. 또한 1.4B 파라미터 이상의 Pytorch기반 모델은 Data Parallelism만을 사용할 때 OOM이 발생하지만 ZeRO-2는 13B까지 Model parallelism 없이 Data Parallelism을 사용할 수 있다.

2. DeepSpeed의 Features

3. ZeRO: Zero Redundancy Optimizer
DeepSpeed ZeRO는 Data & Model Parallelism에서 메모리의 Redundancy를 제거하여 학습 속도를 크게 향상시키고 학습 비용을 낮출 수 있다.
DGX-2 (V100 x16. 32GB버전)에서 Megatron으로 T-NLG 학습하려면 1024개의 GPU가 필요하지만, GPU당 throughput은 9 TFlops (TensorCore기준)으로 V100가 제공하는 최대 125TFlops의 10%도 안 되는 낮은 성능을 보인다. DGX-2로 512 batch size를 돌리기 위해 1024개의 GPU(DGX-2 64대)를 사용한다면 매우 비효율적일 수 밖에 없다.
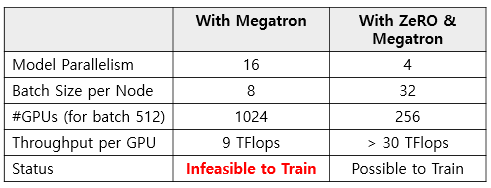
ZeRO는 학습 시 메모리 footprint를 줄여 더 작은 Model Parallelism 수준과 더 큰 batch size로 성능을 향상시킨다. 실제 ZeRO는 Megatron에 비해 GPU당 30 Tflops 이상의 성능을 이끌어내며 3 배이상의 throughput 향상 효과를 거둘 수 있으며 512 batch size에 256 GPU만을 필요하여 GPU의 사용량을 1/4로 줄일 수 있다.
ZeRO는 메모리 소비 스펙트럼을 분석하여 Model States와 Residual States로 나누어 각각에 대한 솔루션을 제안한다. 메모리의 대부분을 Model States가 점유하고 나머지 Residual States으로 구성된다.
- Model States: Parameters, Gradients, Optimizer states
- Residual States: Activation, Temporary Buffer, Fragmented Memory 등
ZeRO의 제품군은 다음과 같다.
ZeRO-1
- ZeRO-DP(ZeRO powered Data Parallelism)
- Model States 문제를 해결하기 위한 솔루션
ZeRO-2
- ZeRO-R(ZeRO powered Residual States Solutions)
- Residual States 문제를 해결하기 위한 솔루션
ZeRO-3
- ZeRO-Offload
- CPU offloading
ZeRO-Inifinity
- …
4. ZeRO-1 & ZeRO-2
ZeRO-DP(Data Parallelism)는 Model States 문제를 해결하기 위한 솔루션으로 기존 Data Parallelism+Model Parallelism의 한계를 극복한다. ZeRO-DP는 model states를 분할하여 data-parallel 과정의 메모리 redundancy를 제거한다. Data-parallelism시 model states을 각 디바이스에 복제하면서 메모리 redundancy가 발생하게 된다.
따라서 ZeRO-DP는 디바이스 메모리가 model states를 공유할만큼 크다면 임의 크기 모델에 사용할 수 있다. ZeRO는 3가지 주요 최적화 단계가 있다.
- Stage-1. Optimizer States Partitioning (Pos): 4x 메모리 절감
- Stage-2. Optimizer States Partitioning+Gradient Partitioning (Pos+g): 8x 메모리 절감
- Stage-3. Optimizer States Partitioning+Gradient Partitioning+Parameter Partitioning (Pos+g+p): GPU의 개수에 따라 메모리 절감. 예) 64 GPUs를 사용하면 64x 메모리 절감. Comm. Volume은 50% 증가함
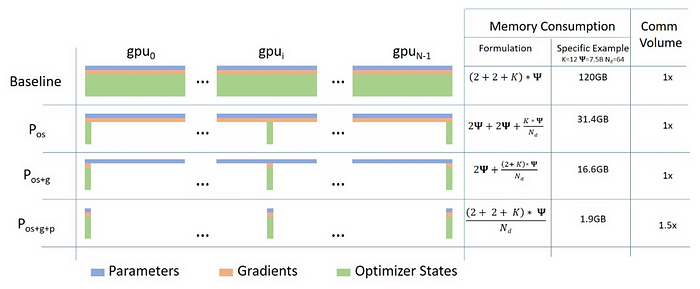
위 그림에서 2+2+K 항목은 parameters, gradients, optimizer states에 어떠한 정밀도(FP16 또는 FP32 )를 사용하느냐, optimizer 종류에 따라 달라진다. Parameters와 Gradient는 FP16을 사용하므로 2+2로 표현되며, K는 optimizer에 따른 고유 상수항으로 Adam optimizer states의 경우 K=12 (Variance+ +Momentum+Parameters)이다.
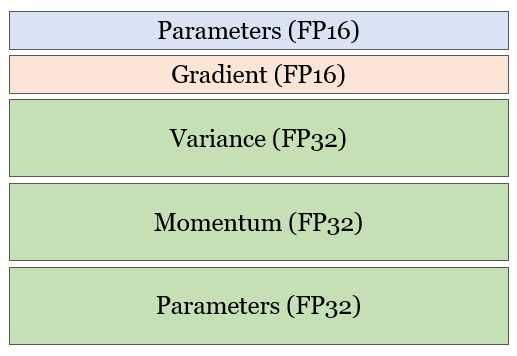
ZeRO-1:
ZeRO-DP의 Optimizer States Partitioning 기법을 ZeRO-1이라고 한다.
ZeRO-2:
ZeRO-1과 비교하여 ZeRO-2는 DeepSpeed로 학습할 수 있는 모델의 크기를 2x 늘려 학습 효율성을 크게 향상시킨다. ZeRO-2는 Residual States 문제를 해결하기 위한 솔루션으로 gradient, activation, fragmented 메모리를 절감하기 위한 기술을 소개한다.
ZeRO-2는 model states, activation, fragmented 메모리를 포함한 학습 중 메모리 소비의 전체 스펙트럼을 최적화한다.
- Model State Memory: ZeRO-1의 optimizer States Partitioning(Stage-1)에 Gradient Partitioning를 추가하여(Stage-2) ZeRO-2는 디바이스당 메모리 소비를 2배 더 줄인다.
- Activation Memory: activation partitioning을 통해 model parallelism에서 activation 복제를 제거한다. 모델 사이즈가 매우 크거나 메모리가 극도로 제한된 경우라면 activation을 CPU 메모리로 보낸다.
- Fragmented Memory: tensor들의 생명 주기가 달라 학습시 메모리 단편화가 발생한다. 메모리 단편화로 인해 연속적인 메모리의 부족으로 가용 메모리가 남아 있었음에도 불구하고 메모리 할당에 실패한다. ZeRO-2는 메모리 단편화를 제거하여 공간을 효율적으로 활용한다.
- Constant Size Buffer: All-reduce에 사용되는 Bucket사이즈를 Constant하게 유지하는 기법이다. Bucket의 사이즈를 모델에 의존하지 어느정도 크게 유지하기만 해도 충분히 좋은 효율성을 얻을 수 있다.
ZeRO-1과 ZeRO-2 비교
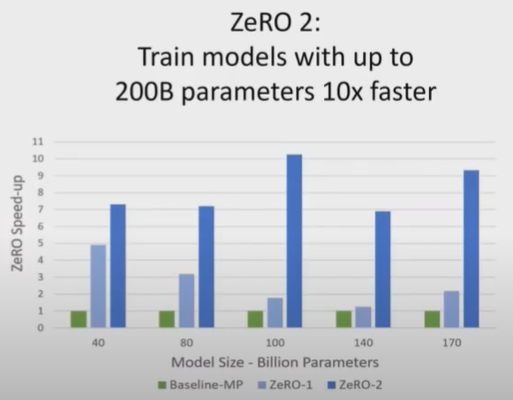
ZeRO-2는 200B 모델까지 학습 가능하고 Megatron에 비해 학습속도가 10배 더 향샹된다. 또한 ZeRO-1를 적용하는 것보다 ZeRO-2를 적용할 때 학습 속도 향상이 월등하다.
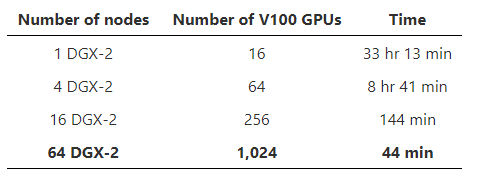
BERT training 결과: 44분 (1024 V100 GPUs)
NVIDIA BERT와 HuggingFace BERT와 DeepSpeed ZeRO의 Single GPU 성능을 비교한 결과이다. DeepSpeed ZeRO는 128 seq 길이에서 64 Tflops, 512 seq 길이에서 53 Tflops를 달성하여 NVIDIA BERT에 비해 최대 28%, HuggingFace BERT에 비해 최대 62% 향상된 결과를 제공한다.
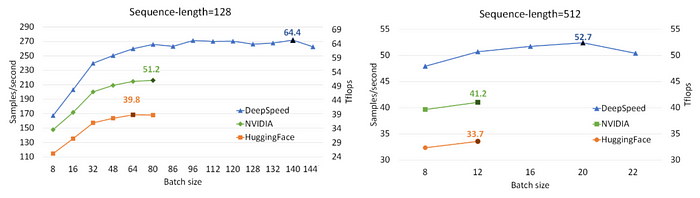
1024 GPUs를 사용하였을 때 NVIDIA BERT를 이용하였을 때 67분이 걸리고 DeepSpeed는 44분 걸리므로 학습 시간이 34% 단축된다.
5. ZeRO-3
ZeRO-Offload라고 불리우는 ZeRO-3는 gradients, optimizer states를 CPU 메모리로 offloading하고 optimizer 연산을 CPU로 offloading한다. Parameters와 forward & backward 연산은 GPU에서 유지한다.
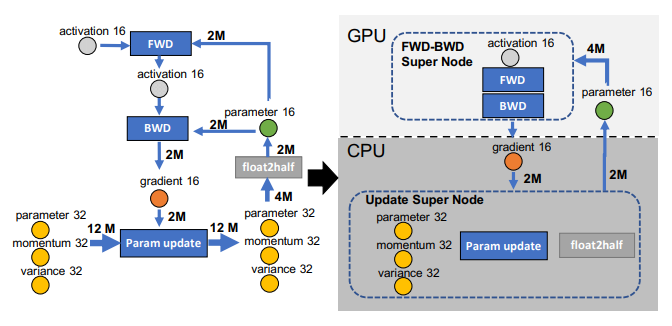
위의 그림은 ZeRO-Offload의 CPU offload를 방식을 설명한다.
CPU 연산 제약
CPU 연산 throughput은 GPU 연산 throughput이 훨씬 느리기 때문에 CPU에 compute-intensive 연산을 offloading하는 것을 피해야 한다. ZeRO-Offload는 optimizer 연산 및 weight updates를 CPU가 수행한다.
- Compute Complexity of DL training per iteration: O(MB) → GPU
- Norm calculations, weight updates: O(M) → CPU으로 offload
(M: Model Size, B:Batch size)
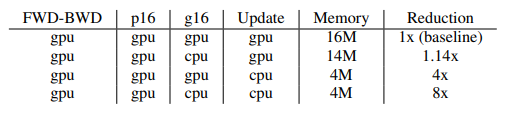
메모리 절감 최대화
- GPU: FWD-BWD, parameter (FP16)
- CPU: gradient (FP16)과 optimizer states(Super Node: parameter FP32, momentum FP32, variance FP32)를 CPU로 offload한다.
ZeRO-Offload 스케줄링
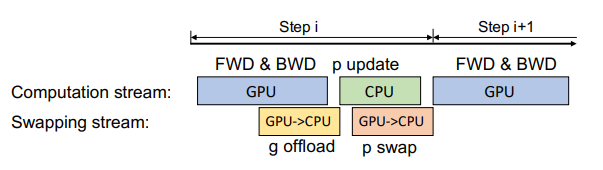
ZeRO-Offload의 Single GPU 스케줄링 전략은 다음과 같다.
- GPU에서 연산된 gradient FP16를 GPU 에서 CPU Memory로 전달함 (Transferring이 backward propagation과 함께 중첩되어 comm. cost가 숨겨지는 것이 가능함)
- CPU는 optimizer 연산을 실행하며 parameter FP32를 업데이트함
- CPU가 업데이트한 parameter는 FP32 → FP16 변환 후 GPU로 복사됨
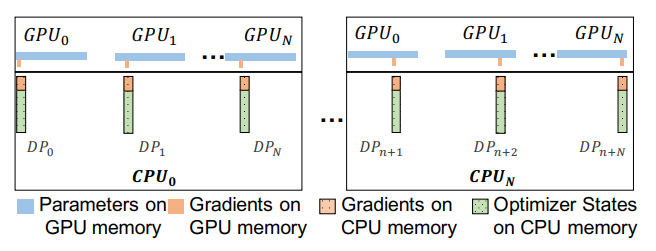
이를 Multi-GPU로 Scaling하기 위해 ZeRO-2를 사용하여 gradient를 계산한다.
최적화된 CPU 실행
Adam optimizer를 CPU에 최적화하기 위해 1) SIMD vector instruction, 2) Loop unrolling, 3) OMP Multithreading를 개선하여 SOTA pytorch 구현에 비해 더 빠른 Adam optimizer를 구현하였다.
또한 One-Step Delayed Parameter Update(DPU)를 구현하였다. CPU 연산은 다음과 같은 경우 병목 현상이 발생할 수 있다.
GPU compute time ≤ CPU compute time
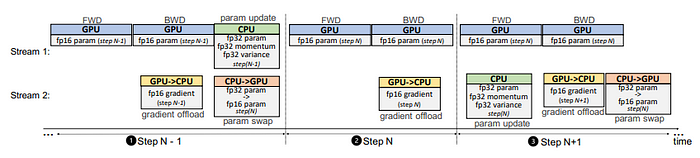
- (1) Step N-1: 불안정한 학습을 피하기 위해 DPU 없이 학습함
- (2) Step N: GPU → CPU로 gradient FP16를 복사. CPU는 parameter 업데이트를 하지 않고 skip함
- (3) Step N+1: GPU가 forward 연산 시 CPU는 Step N으로부터 확보된 gradient FP16을 이용하여 optimizer 연산과 parameter를 업데이트함.
6. ZeRO-Infinity
7. 레퍼런스
[1] ZeRO: Memory Optimizations Toward Training Trillion Parameter Models
[2] ZeRO-Offload: Democratizing Billion-Scale Model Training
[3] ZeRO & DeepSpeed: New system optimizations enable training models with over 100 billion parameters
[4] ZeRO-2 & DeepSpeed: Shattering barriers of deep learning speed & scale
[5] DeepSpeed: Extreme-scale model training for everyone
